Hace unos días leyendo un artículo me acordé sobre la API de windows IsDebuggerPresent localizada en Kernel32.dll para detectar si hay un depurador actuando sobre el programa se me ocurrió escribir una serie de artículos cortos sobre técnicas para detectar depuradores en Linux.
Es realmente frecuente encontrar en ejecutables técnicas para detectar si un depurador está activo o no, en función de si hay un depurador activo realizará una acción diferente a la acción realizada si no hubiese ningún depurador. Estas técnicas suelen ser usadas por aquellos programas que no se quiere que se le haga ingeniería inversa y de esta manera dificultar el estudio del ejecutable.
Unos cuantos ejemplo de ejecutables que usan este tipo de técnicas son los malware y los virus, pero también sistemas de empaquetado de ejecutables y sistemas de protección anticopia.
La primera técnica que vamos a ver se basa en el principio de que en Linux, un sistema que está siendo depurado por un proceso no puede ser depurado de nuevo por otro proceso. En linux la mayoría de depuradores usan la llamada al sistema ptrace para realizar su trabajo, de tal manera que si nosotros en nuestro programa llamamos a dicha función evitaremos que podamos ser depurados.
Si ejecutamos este programa desde la shell y luego probamos a ejecutarlo en gdb obtenemos

Vemos que si se ejecuta directamente sobre la shell nos dice que no hay depurador pero en cuanto lo ejecutamos en gdb nos dice ¡Depurador detectado!
Pero no solo eso, si lo ejecutamos con ltrace

y con strace

Vemos que obtenemos el mismo resultado ¡Depurador detectado!. En la última imagen se ve un poco mejor que es lo que realmente está pasando, vemos que cuando hace la llamada a ptrace nos devuelve -1
ptrace(PTRACE_TRACEME, 0, 0x1, 0) = -1 EPERM (Operation not permitted)
Esto ocurre porque el programa está siendo traceado por strace y la llamada a ptrace de nuestro código no está permitida cuando ya hay otro ptrace en ejecución, el de strace.
Una de las formas mas sencillas para combatir esta técnica es modificar EAX a la salida de ptrace. EAX (o RAX en arquitecturas de 64 bits) contendrá el resultado devuelto por ptrace, que como hemos visto arriba, cuando hay un depurador activo es -1. Si modificamos y ponemos un valor 0 o mayor habremos conseguido saltarnos la técnica.
Para ello podemos cargar el programa en gdb, poner un breakpoint en main y ver cual es la instrucción inmediatamente posterior a ptrace y poner un breakpoint allí.

si ponemos un breakpoint en la dirección 0x0804846c y continuamos la ejecución veremos que en eax devolverá -1 (como nos avisaba strace) si nosotros cambiamos este valor por 0 habremos conseguido saltarnos la protección

Esta técnica es bastante sencilla pero requiere la modificación del registro EAX, otra técnica sería parchear el ejecutable y aquí tenemos bastantes opciones, podemos eliminar el call a ptrace y sustituirlo por nops, podríamos invertir el salto jns que hay a continuación de test, podríamos ponerle nops a ese salto, podríamos cambiar la instrucción test y cambiarla por alguna mas apropiada, etc.
Estas técnicas comentadas arriba son técnicas intrusivas porque requieren la modificación del binario o de la memoria del proceso en tiempo de ejecución, podemos realizar un enfoque mucho menos intrusivo si conseguimos que la llamada a ptrace devuelva automáticamente 0 (o cualquier número positivo).
Para ello nos programamos nuestra propia función ptrace
y la compilamos de la siguiente forma
gcc -m32 -shared -fPIC ptrace.c -o ptrace.so
De esta forma le decimos que va a ser una librería compartida (-shared) y que el código va a ser independiente de la posición (-fPIC), esto lo que hace es que en el binario en vez de guardar direcciones de memoria va a almacenar offset de esta manera esta librería podrá ser cargada en tiempo de ejecución en cualquier posición dentro del espacio virtual del proceso (gracias a esto funciona ASLR, aquí explico como funciona ASLR y como romper su seguridad: http://bitybyte.angelluispg.es/2016/11/13/bypassing-aslr/)
Ahora podríamos decirle a Linux que utilice nuestro ptrace.so en vez de la librería del sistema para ello tendríamos que establecer la siguiente variable de entorno
export LD_PRELOAD=./ptrace.so
En mi caso no me interesa exportarla en la shell de linux así que la voy a exportar dentro de gdb con
set environment LD_PRELOAD ./ptrace.so
Si ahora ejecutamos el programa que implementa la técnica antidepuración vemos
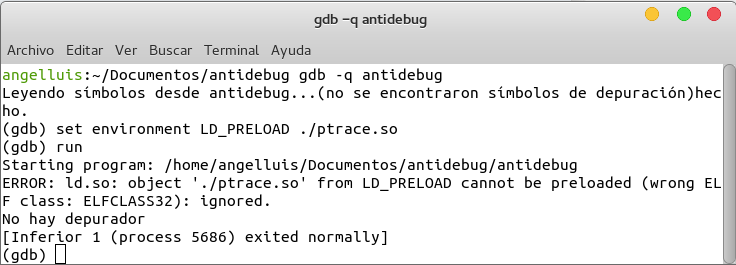
Efectivamente hemos conseguido evitar la la técnica antidepuración de una forma más limpia.


